Seoul, Korea, 7-11 September 1999

Presenter: Professor Graham Greenleaf,
University of New South Wales, Australia
http://www2.austlii.edu.au/~graham/ mailto:graham@austlii.edu.au
Co-authors[*] : Graham Greenleaf, Daniel Austin, Philip Chung, Andrew Mowbray, Jill Matthews and Madeleine Davis of AustLII (http://www.austlii.edu.au/)
Version: This is the first version of a work in progress which
may be found at http://www2.austlii.edu.au/~graham/publications/World_Law/
. A version of the paper was presented at AustLII's Law via the Internet
'99 Conference, 21-23 July 1999, University of Technology, Sydney.
There are also extensive collections of case law from about 20 countries, particularly from North America and Australasia and some European courts, but also courts from India, Korea, Brazil and other countries. The Parliaments of dozens of countries have Web pages, and these contain many significant resources concerning legislation and law reform. Law reform commissions and similar bodies are starting to make their reports and working papers available via the Web. There are specialist university and other centres which provide very large specialist collections of materials in areas such as constitutional law, trade law, the law of the sea and human rights.
Despite the abundance of valuable legal materials already on the Web, and the rapidity with which these materials are expanding, these materials are often very difficult to find, since they are scattered across thousands of Web sites located all around the world. As we shall see, the tools we have used for internet legal research until now do not serve us well enough.
However, the availability of legal information on the World-Wide-Web is of considerable importance to developing counties, in Asia and elsewhere. Law libraries with reasonably comprehensive and up-to-date collections of legislation, case law and law reform reports, are virtually unknown in the developing world, and the costs of maintaining them are prohibitive. Access to large online commercial services such as Lexis is also prohibitive for most lawyers in developing countries. This is the principal reason that the Asian Development Bank has funded the development of Project DIAL (Development of the Internet for Asian Law)[3]http://www.austlii.edu.au/au/special/dial/] (one subject of this paper): to provide a means by which legislative and law reform personnel can obtain access to comparative legislative and law reform models. It is of equal importance for superior Courts in developing countries to have access to the decisions of similar Courts throughout the world. It is not only the legislation or case law of the developed countries that is of interest and importance: a legislator in Mongolia might find their best model for a Buy-Operate-Transfer (BOT) law from a Kazakstan Web site, and the Supreme Court of a small Pacific Islands country is likely to find the most important precedents for its decisions in the decisions (currently almost completely unobtainable) of similar Pacific Island states.
Legal information on the Internet is also important to developing countries for a quite different reason: the provision via the Internet of comprehensive and up-to-date information about a country's laws and legal system can be a striking demonstration of the transparency of a country's legal system. This is likely to be of considerable imporartance to potential foreign investors, both in symbolic terms and in facilitating efficient and low cost legal advice necessary for investment decisions to be made. A recent example is the proliferation of govenment agency Web sites in Mongolia which provide the legislation that they adminster[4]: it would be very difficult and expensive to obtain that legislation by any other means.
Catalogs are where individual Web sites are classified by hand according to various classificatory schemes. Because of the human intelligence and effort involved, they are also called 'intellectual' indexes. Usually, such indexes only provide the title, URL[5] and perhaps a brief description of each site indexed. Yahoo![6]http://www.yahoo.com/] is a well known example of an internet-wide catalog or intellectual index of the Web (ie one which is not law-specific).
'Search engine', in the Web context, has become a shorthand way of referring to the combination of a 'Web robot' and the data it gathers, and the text retrieval software used to search that data. A program (variously called a `Web robot' or `Web spider') traverses the Web, downloading every page it encounters, so that every word on every page can be converted into one very large word occurrence index ('concordance') which can be searched by the text retrieval software. They can also be called 'automatic indexes'. When the search engine displays a URL as a result of a search, that URL is to the original site, not to a mirror on the remote site. Alta Vista, Northern Light, Hot Bot, Excite and Infoseek are well-known `general purpose' search engines that search an index created by a Web spider, and where the Web spider goes to all types of subject matter. They have only existed since Alta Vista's creation in 1996. The principle advantage of this approach that it is possible to search every word that has been indexed, not just the titles and brief summary of what is on the site. About 85% of internet users use search engines to locate information[7].
Combinations of catalogs and search engines on the one site are now becoming more common, and such combinations are often referred to as 'portals'. Some catalogs are now attempting the automated or semi-automated classfication of new Web sites located by a Web spider (for example, Excite Australia[8]). This approach is potentially promising but has not yet been shown to produce useful systems for legal research.
Despite the existence of these research aids, finding legal information on the internet is surprisingly difficult, partly because neither catalogs nor search engines used alone can provide a satsifactory solution. This is particularly in relation to internet-wide (ie not law-specific) catalogs and search engines. These difficulties will now be summarised[9].
Catalogs are hard to maintain. As the quantity of legal material on the internet grows, the sites that contain significant legal information grow so numerous, and some are so large, that it is difficult to maintain catalogs at all, and particularly to maintain them with any depth of indexing of each site. The best that can be hoped for is that sites with significant legal materials are identified in the index, even though there is no detailed description of their content. For example, it soon becomes impossible to include in a catalog the content of each piece of legislation, each case, or each journal article included on a large site.
As a result, we can say that catalogs are inherently shallow - even when they are good at identifying important law sites, they cannot index very deeply into those sites.
General search engines are not comprehensive. There are very good internet-wide search engines, but they are nowhere near as comprehensive as people often assume. A July 1999 report in Nature by Lawrence and Giles[14] shows that of eleven major search engines tested (includingAlta Vista, Northern Light, Hot Bot, Excite and Infoseek ) the search coverage they provided of the estimated 800M pages on the Web was 16% at best (Northern Light) and down to 5.6% (Excite), with some not named here even lower.
There are a number of reasons, other than the rapdily expanding size of the Web, for the lack of comprehensiveness of search engines based on automated Web spiders. They include the following[15]http://searchenginewatch.com/size.htm]:
Why do search engines index such a small fraction of the Web? There may be a point beyond which it is not economical for them to improve their coverage or timeliness. The engines may be limited by the scalability of their indexing and retrieval technology, or by network bandwidth. Larger indexes mean greater hardware and maintenance expenses, and more processing time for at least some queries on retrieval. Therefore, larger indexes cost more to create, and slow the response time on average.There are diminishing returns to indexing all of the Web, because most queries made to the search engines can be satisfied with a relatively small database. Search engines might generate more revenue by putting resources into other areas (for example, free e-mail).The combined coverage of all of the search engines tested by Lawrence and Giles was estimated at 42% of the total number of Web pages, a decline from 60% in their 1997 study. They agree that use of meta-search engines such as MetaCrawler will provide a more comprehensive search. However, it seems from their research that the best possible coverage would still only be about 42%, and even then this would depend on maximum coverage and sorting efficiency of the meta-search engine, so the real figure is likely to be somewhere between 16% and 42%.
There are other significant problems with general purpose search engines which stem from the ambitious nature of their task of indexing all information on the Web irrespective of its subject matter:
Using different search engines can be confusing Even if a law site does have its own search engine, users who wish to find legal materials on different sites can also be easily confused by the need to use different search engines with different search commands.
The answer we propose is in part a technical solution, a limited area search engine for law, but to a large extent the success of the technical component will depend on an organisational element, the creation of a multi-national group of collaborators who are willing to make joint use of the technical tools we have developed in order to create and sustain a world-wide legal research facility.
The following diagram explains this relationship, from the perspective of the indexer and the user.
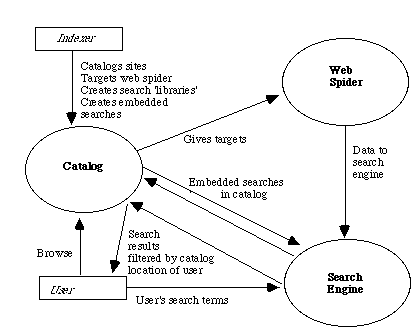
Interactions in the use of a World Law/DIAL's limited area search engine
Consequently, the way in which we are now envisaging the World Law / DIAL project is that, while most of the organisation of the content indexing and much of the substantive indexing will be carried out by AustLII staff, wherever possible we will invite appropriate authorites from other countries, and other language and subject specialities, to participate in the cataloging process as 'indexing partners' for particular parts of the catalog.
There are a number of ways in which such partnerships can proceed, ranging from a partner periodically emailing lists of proposed URLs to be added to our pages to AustLII's indexers (who would add them to the relevant pages and send the Web spider); to our indexers checking a partner site regularly for any additional links which should be added to our pages; to a remotely located indexer being provided with password access to the editing interface to World Law such that they can add links and change sub-categories in 'their' parts of the index but not elsewhere. The editing interface of World Law is via the Web, so contributing editors can be located anywhere with Web access.
Wherever collaboration occurs, it will be acknowledged on those pages of the catalog where the collaboration is based, by inclusion under the 'Contributor' heading of the logo (or name) of the contributing organisation or person and a link to their Web site. For example, Australia's Department of Foreign Affairs and Trade contributes content to the creation of our 'Treaties and International Agreements' pages, which is acknowledged as shown below.

Some of the advantages of this approach for our indexing partners are that they will obtain additional users through referrals from the World Law pages, and if they wish they will also be able to place CGI search interfaces on their own pages which will search over the full texts indexed by our Web spider, but only only the part of AustLII's index relevant to them.
We are only now starting this process of creating partnerships, so it is too early to report on its success. Our first international partnership is being established between Ralph Amissah's Lex Mercatoria site in Norway[31] and World Law's International Trade pages[32], Other partnerships are being negotiated.
The first opportunity for extensive testing of the targeted Web spider was in Project DIAL[33]http://www.austlii.edu.au/au/dial/], a project for the Asian Development Bank which aims to increase the accessibility of legislation on the internet. The Web-spider search facility, DIAL Search[34]http://www.austlii.edu.au/au/special/dial/DIALsearch.html], was released on the Web in August 1997 and allowed searches of legislation and legislation-related material from many countries. The World Law / DIAL facilities were demonstrated at the Australian Society of Indexers' Conference in 1997[35]. The more general version of the targeted Web spider was made available from AustLII's home page as `World Law Search' in Februrary 1998, when non-legislative material started to be added by the Web-spider. Two test 'Libraries' were added to allow searches to be restricted to legislative materials and to other internet law indexes - the precursor of the search limitation facilities which have now been added.
In June 1999 the Asian Development Bank entered into a three year agreement for AustLII to develop and host the full-scale Project DIAL facility, as a Regional Techncial Assistance (RETA) of the Bank. The value of the RETA is approximately A$1 M, with nearly a half of those funds being used to assist and train users in the Bank's Developing Member Countries (DMCs) of the Bank.
During 1999 there has been a major redevelopment of the search facilities in World Law / DIAL, so that the scope of searches can be limited by the location in the catalog from where the user does the search. This enables users to limit their search scope (thus increasing precision) without having to undersand any search commands in order to do so. It is the major single technical innovation in World Law / DIAL.
JURIST[36] launched in January 1998 what it calls a `Limited Area Search Engine (LASE)' to make searchable all home pages of law Professors and course pages of law subjects in its index.
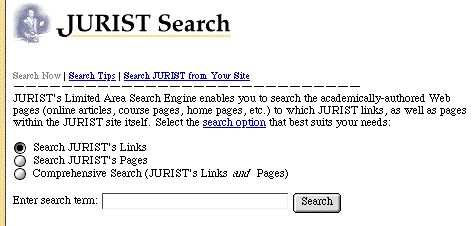
JURIST uses the Argos LASE which, according to its developers, was `the first peer-reviewed, limited area search engine (LASE) on the World-Wide Web'[37]http://argos.evansville.edu/about.htm] at the time of its release in October 1996. Argos was developed to provide a more precise means of searching for scholarly literature on the ancient and medieval world. It's development was prompted by the same shortcomings with Internet-wide search engines as we have identified in the preceding discussion[38]http://argos.evansville.edu/about.htm]:
At the time of this writing, a search for "Plato" on the Internet search engine, Infoseek, returned 1,506 responses. Of the first ten of these, only five had anything to do with the Plato that lived in ancient Greece, and one of these was a popular piece on the lost city of Atlantis. ... Add to this broad range of responses the fact that Infoseek returns ten entries per page, making it necessary to examine one hundred and fifty one pages of entries, many of which are irrelevant to a scholarly search of "Plato," and the result is a process that is frustrating and inefficient.They identify advantages of the alternative, `targeted' approach:
By limiting the range of the search engine, a LASE strips out many unwanted references... The result is a higher quality index built for a specific purpose and for a smaller audience. Furthermore, the quality of the index, its purpose and the level of specialization expected of its intended audience are variables that can be manipulated with LASE technology.They also note that, because of its limited scope, it is possible for Argos to update weekly the indexes to all the sites it covers, rather than the couple of months that (in their experience) are taken by Internet-wide search engines to update sites. They estimate that this means that 98% of all links found by their search engine work at any given time.

Another example is that Knowledge Basket, the New Zealand Internet content provider, released Legal Search New Zealand[39]http://202.37.88.18/search/legsearch.html] in December 1997. It uses the Verity Web robot and Topic search engine, and makes searchable 25 New Zealand law sites at present. The advantages they claim for this approach are similar to those described above[40]http://www.knowledge-basket.co.nz/kete/nzsearch.html].
Some features of the catalog structure are:


You can always get back to the start of the catalog by clicking on '>> World >>' (or on 'Australia' in the Australian part of the catalog). If you are in the 'World' part of the catalog and you want to get to a particular country page (eg Vietnam), click on '>> World >>' then '>> Countries >>' and then select 'Vietnam@'.

Targeting the Web spider to start indexing at the correct page, so that it when it indexes all other pages to which its starting page is directly or indirectly linked, but are equal to or below the start page in the server's file hierarchy, it indexes all and only the desired pages, is a complex task. Some desired sets of data cannot be indexed because of the `noise' they will bring with them. For others, it is impossible to find an appropriately located `table of contents' page to use as the `start page'. Other `problems of targeting' have also been identified[42]http://www2.austlii.edu.au/~graham/Futureproof/indexers-6.html#Heading22].
Another maintenance problem is that the web spider is sometimes sent to a URL which does exist, but for some reason cannot download the intended pages from that starting point. Conversely, sometimes an editor does not notice that by starting the web spider from a particular page it will download far more pages than are intended. To assist in addressing these problems, the program that controls the sending of Web spiders ('Wallace') sends a report to the indexers if the Web spider downloads only a couple of pages from a URL, or downloads more pages than a pre-set limit (currently 1,000).
There is now one interface to both the catalog and the search engine, with a search form located at the top of each catalog page (illustrated below). The very unusual feature of the search facilities in World Law / DIAL is that the scope of the search is (in default) limited by the location in the catalog from which the user carries out the search. In other words, if the search is from the 'World>> Legislation' page, it will search over all legislation from any country (but only legislation); if it is from the 'World >> Countries >> Germany' page it will search only over sites related to German law; and if it is from the 'World >> Countries >> Germany >> Legislation' page it will search only German legislation.
Search results are displayed with catalog pages ('categories') listed first, and then with the full texts of remote documents ('documents') listed. Both lists are sorted into likely order of relevance to the search query (relevance ranking).
To put it very simply, the way in which the search restriction mechanism works is that the search is first done over all pages retrieved by the Web spider, but before the results are displayed to the user they are 'filtered' by the URLs listed on the page indexed and its related pages, so that only relevant pages are displayed.
To broaden or narrow your search scope, you go to a more appropriate page in the catalog. Context determines search scope.

To search over everything available, the user could go back to the 'World' page (by clicking on 'World') and search from there. Alternatively, no matter where you are in the catalog, you can search everything ('World') by selecting 'All World Law' (from the 'in' option) instead of the default option limiting the search scope, as shown above. At present, the 'All World Law' option is by far the fastest way to search. But the more restricted search scopes may give greater precision. Test for what works best until the restricted scope searches become faster.

The default option is 'any of these words'. If you want to do any other type of search, you must change this default.
Users can also enter text in any form (eg `I want laws on tax and
bankruptcy' or `tax taxation bankrupt bankruptcy') without knowing about
search connectors, truncation etc. Results are ranked according to likely
relevance, so the user will (usually) obtain a useful list of search results,
although often not as complete as a boolean search can provide. This is
the search method recommended for inexperienced users, and is the default
option. (This is AustLII's Freeform (Ranked Results) search method.)
 appears next to the listing
in the catalog. If you click on the words 'search site' or the
appears next to the listing
in the catalog. If you click on the words 'search site' or the 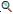 icon, then you are taken to a 'Search Site' page which automatically limits
the scope of the search to the one site selected. This function allows
World Law Search to be used to search specific sites which have no search
engine of their own, or have a search engine which does not have the same
features as the SINO search engine used for DIAL Search. It also overcomes
the need for users to learn to use the features of multiple search engines.
icon, then you are taken to a 'Search Site' page which automatically limits
the scope of the search to the one site selected. This function allows
World Law Search to be used to search specific sites which have no search
engine of their own, or have a search engine which does not have the same
features as the SINO search engine used for DIAL Search. It also overcomes
the need for users to learn to use the features of multiple search engines.
In the following, two of the sites may be searched, but the other two may not:

When a site is selected, a 'Search selected site' page is presented and searches from that page are limited to the site selected:

The following example is the results of a search for the phrase 'financial intelligence' over the whole of World Law.
The percentages given against each item found are based on the most relevant item being given a score of 100% (provided it contains all search terms - otherwise less), and all subsequent items being given a percentage ranking proportional to that, according to their likely relevance.
The search form containing the executed search is displayed at the top of each search results page, so any search can be modified easily in light of the results obtained.
The present method of displaying results relies upon the remote site attaching informative titles to its HTML pages, as it is these titles that are displayed. While most sites do achieve this to a reasonable degree (as can be seen from the above example), some sites fail to provide any title at all, so that only the URL of the site can be displayed in default. This is not informative enough. A number of alternatives are under consideration. One is to display the first 50 words or so of the document, similarly to what is done in Alta Vista. A second is to include the name of the site from which each the document comes (as described in the catalog), or perhaps the name of the catalog page, after the display of the title. This would at least make it easier to recognise which countries and systems particular items are from. These choices have significant processing overheads, and we are concerned not to unduly slow the delivery of search results.
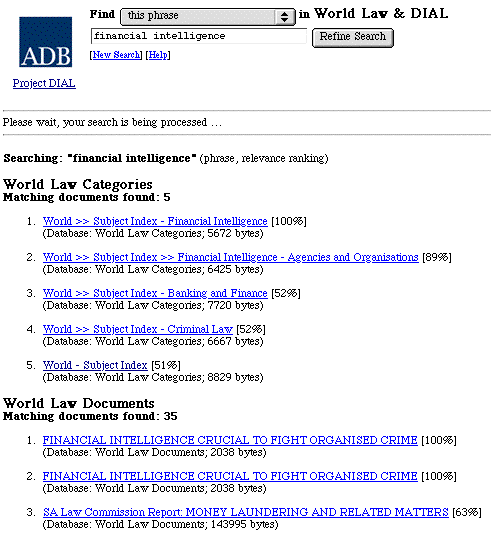
For example, on the Intellectual Property Subject Index page (below) there are various stored searches for different aspects of intellectual property. The hypertext links that appear on the page are each a search of World Law that a legal indexer has created in order to find a general set of documents which relate to the topics of the searches. For example, the link entitled 'World Law search: trade marks and related laws' is in fact a stored boolean search for 'trade mark or trademark or unfair competition or passing off'. These examples are relatively simple searches, but searches of any complexity can be stored.
ttp://beta.austlii.edu.au/links/World/Subject_Index/Intellectual_Property/Stored_Searches/index.htmlh
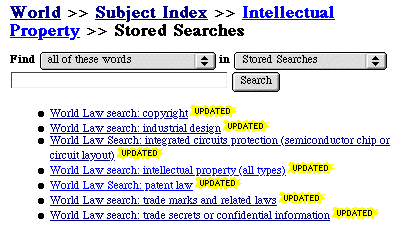
The significance of these `stored searches' of DIAL Search in the DIAL Index is twofold:


Because the relevance ranking tends to give short documents and documents that use a search term in a title, many of the internet law indexes that have a separate page for that country will appear near the top of the list, so the user can they quickly review existing intellectual law indexes for that country. Here, the first 15 items found are a mixture of the 'Fiji' pages in other internet law indexes (JurWeb, ICL and ILRG), documents about human rights compliance, and Asian Development Bank law and development project notices.
In the longer term work will be done on the use of legal thesauri to create large scale sets of stored searches and their distribution through the catalog. Good thesaurii are difficult to find on the web.
The key to the development of a genuinly world-wide free access catalog and search facility for law is definitely the formation of 'indexing partnerships' with legal institutions with expertise in other key languages for materials on the Web (Chinese, French, Spanish, German, Russian). Development of the technical capacity to handle different character sets is also required.
As the range of non-English materials searchable in World Laws increases, it is likely to become valuable to be able to limit searches to materials in a particular language. This will probably be implemented by the indexer indicating the language of non-English materials at the time of adding them to World Law Search, with an option for users to exclude or include materials in particular languages.

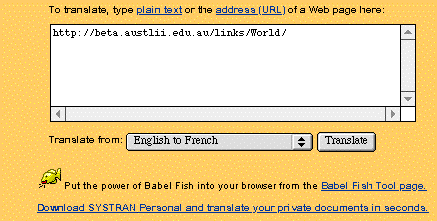
The resulting translation seems adequate to convey the meaning of most of the items on the page.
The Alta Vista/Systran translation facility is at present limited to translations from English to French, Spanish, Portuguese, Italian, or German, and vice-versa. This translation facility is also only a prototype, and sometimes has inadequate processing power to translate very long pages. It is also not recommended to use it to translate documents with complex grammar, or where accuracy is vital (such as legislation). However, for pages such as menus, or lists of search results, it is usually extremely helpful.
The translation facility has uses beyond translations of catalog pages:
At present the languages used cover most common European languages, with translations constructed using the Eurodicautom[45] service.
Translations of country names in a number of Asian languages will be added next to the embedded searches. As these searches are permanent, broad searches of all the documents indexed from time to time, an investment of time in the construction of such searches is probably more effective than equivalent time spent indexing sites in detail.
If World Law succeeds it will be because the technical infrastructure that we are creating, and the collaborative environment within which it is used, is capable of attracting the interest and cooperation of others around the world with a commitment to the provision of free access to legal information via the Internet, and an expertise in some part of the Internet's rapidly expanding legal content.

First DIAL training session for Mongolian teachers from the Legal Retraining Centre, Ulaan Baatar, held at the University of Melbourne on 9 July 1999.
The Asian Development Bank's funding of the training component of Project DIAL is a significant experiment in achieving this broader goal. DIAL involves in-country training of government lawyers (and others as resources permit) in seven Developing Member Countries (DMCs) of the Bank: Vietnam, Philippines, China, India, Pakistan, Indonesia and Mongolia. The DIAL training team will involve creation of a team from eight countries: local trainers in each of these DMCs, a Regional Training Coordinator from the Philippines[47], and the DIAL lead consultants at AustLII. 'Train the trainer' courses are planned to begin in Mongolia, the Philippines and Vietnam during 1999, and in the other countries in 2000. In addition there will be on-line training materials that anyone can access, and DIAL-user email list where anyone trained in DIAL use will be able to receive online support from the DIAL training team in any aspect of Internet legal research.
[1]
For more details see part '2.1. The potential 'world law library' on the
Internet' - at http://www2.austlii.edu.au/~graham/DIAL_Report/Report-2.1.html
- in Greenleaf (1998)
[4] See http://beta.austlii.edu.au/links/World/Countries/Mongolia/Legislation/index.html for examples
[5] `Universal Resource Locator' or internet address of a Web page.
[7] Lawrence and Giles 1999
[8] http://www.excite.com.au/
[9] For the detailed arguments see '2.2. Finding law on the net - Why is it so difficult?' - at http://www2.austlii.edu.au/~graham/DIAL_Report/Report-2.2.html - in Greenleaf 1998.
[10] This section summarises part 2.3. 'Intellectual indexes (directories) for law' - http://www2.austlii.edu.au/~graham/DIAL_Report/Report-2.3.html - in Greenleaf 1998.
[11] See http://beta.austlii.edu.au/links/World/Other_Indexes_and_Search_Engines/ for many examples.
[12] http://dir.yahoo.com/Government/Law/
[13] This part draws on part 2.4. 'Automated indexes and Internet-wide search engines' - at http://www2.austlii.edu.au/~graham/DIAL_Report/Report-2.4.html - in Greenleaf 1998
[14] Lawrence and Giles 1999
[15] See Lawrence and Giles 1999, and `How big are the search engines?' (Search Engine Watch) at and references linked therefrom, for detailed discussion of all these matters.
[16] In 1996 it was claimed that Alta Vista only indexed about 10% of the pages of moderately large Web sites (600 to 6,000 pages in the example cited), and not denied by Alta Vista. Alta Vista now claims to index sites without any limit on pages. The claim by John Pike, webmaster of the American Federation of Scientists, and the reply by Alta Vista are available at < >and discussed in `The Alta Vista Size Controversy' on Search Engine Watch.
[17] See Martin Koster `The Web Robots Pages' at <> for details of the operation of Web robots.
[18] See the `Robots Exclusion' page, dealing with both the standard and the Meta Tag for robot exclusion at <>
[19] Lawrence and Giles 1999. Earlier studies in 1996 had estimated theat the best search engine covered about 20% of the then 150 M Web pages.
[20] For example, on Alta Vista, a search for Vietnamese legal materials requires a search which is limited to materials which are located on a server in Vietnam (the `domain:vn' delimiter) or contain `Vietnam or Viet Nam' - and this is still somewhat hit or miss.
[21] Lawrence and Giles 1999
[22] Exmaples are Google - <http://www.googel.com> - and Direct Hit.
[23] as at Janurary 1998 - see Greenleaf 1998
[24] Aspects of such an approach, in a pre-Internet context, are explored in Greenleaf, Mowbray and van Dijk 1995
[25] Geoffrey King (to 1998), Daniel Austin, Philip Chung and Andrew Mowbray have all worked on the software and systems side of this project.
[26] Developed by Daniel Austin. Geoffrey King developed a previous version.
[27] The names `Wendolyn' and `Wensleydale' have been reserved for future software developed for this project. For further details see
[28] Developed by Daniel Austin
[29] Developed by Andrew Mowbray
[30] http://beta.austlii.edu.au/links/World/Countries/index.html
[31] http://lexmercatoria.net/
[32] http://beta.austlii.edu.au/links/World/Subject_Index/International_Trade/index.html
[35] Greenleaf et al 1997
[36] http://jurist.law.pitt.edu/
[41] http://beta.austlii.edu.au/links/World/Countries/index.html
[43] http://beta.austlii.edu.au/links/World/Countries/Mozambique/index.html
[44] http://beta.austlii.edu.au/links/World/Countries/index.html
[45] http://eurodic.echo.lu/cgi-bin/edicbin/EuroDicWWW.pl
[46] Hinton 1999, Chapter 3
[47]
Rachel Romana of CD Asia and her colleagues