
A 1982 study for the New South Wales government estimated that the volume of NSW Supreme Court cases reported during the 1970s was double that reported during the 1950s (Cooley Douglas Associates Pty Ltd Feasibility Study -- Legal Information Retrieval System for New South Wales, 1982, Box 411 Sydney 2001, p 63).
In the United Kingdom there were an estimated 300,000 reported cases up to 1963 (C Tapper Computers and the Law, 1973, Weidenfeld and Nicholson, pp111-14). Taking United Kingdom and Australian cases together, there must be at least half a million reported cases by now. So, whenever you attempt to retrieve all the relevant caselaw on a particular problem, you are in fact `going fishing' in a sea of caselaw containing over half a million fish.
Lawyers are faced with both a vast and growing accumulation of old information and an accelerating rate of production of new information. Old and new information each raise different problems of retrieval.
However, the importance of old cases should not be exaggerated. Recent research on the citation of pre-1960 NSW Supreme Court cases in the 1983-85 NSW Law Reports shows that there are, on average, only about eight decisions from each year in the 1940-60 period which are now cited at all, and about 3 decisions from each year in the 1900-1930 period which are now cited (DP Lewis `Caselaw databases: the marginal utility of additional historical materials' Vol 3 No 5 (1987) Computer Law & Practice ). So each year's law reports throw up a few decisions which remain demonstrably relevant many years later, but they are the exception rather than the rule.
The continuing relevance of old information gives rise to storage and distribution problems which are also peculiar to lawyers. The costs of each lawyer obtaining a printed copy of a comprehensive library of cases, statutes, and secondary materials, and continuing to do so every year are prohibitively high. Only the largest firms or Government departments can afford even a good library. Most lawyers must use public law libraries or, more likely, ignore some sources they should consult.
Tapper comments on some of the limitations of indexing:
Despite the small number of legal publishers ... there is no uniformity of terms or categories... This is partly because authors often do their own indexing, and partly because in other cases it is usually done by part-time or inexperienced staff with little training or supervision....
Experiments by Tapper showed very little correlation between the terms selected by a number of indexers to index the same material (ibid).
There are also some inherent limitations on citations as a means of
research. As Tapper points out:
Such a technique depends for finding a case upon its either being cited, or its citing other cases. This is not always true even of reported cases. Thus of the 120 cases reported in [1961] 1 All England Reports, sixteen cite no case, and of these no fewer than thirteen seem not so far to have been cited in subsequent cases....
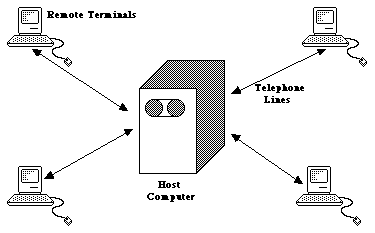
The lawyer or other user who wishes to obtain access to this host computer and its information retrieval system may be located in another part of the same city, or hundreds of miles away. In order to do so, the user will require a computer terminal and other equipment (including a device known as a modem) to connect that terminal, via the telephone system, to the host computer. The user, sometimes called a `remote user', is then said to be `on line' to the host computer. The equipment required by the user is discussed in Chapter 5, but does not concern us now because it is not fundamental to the nature of information retrieval.
So the overall picture is that of a central `host' computer communicating with a the terminals of a variety of `remote' users via the telephone system, as in the illustration below.
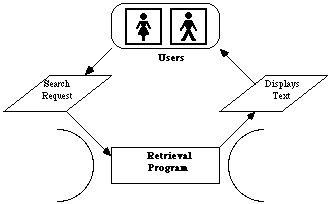
(i) the databases (information or data), the computerised store of information which is to be searched (such as cases and statutes); and
(ii) the retrieval program (software), the computer program which is used to instruct the computer how to search the databases.
These two components have two things in common: they are both stored on the host computer; and they are both stored in the only way in which computers can store information, as binary representations (code or notation) of that information.
A case or a statute, as stored in a computer, can usefully be thought of a an enormously long string of bits, of zeros and ones.
We will use `database' to refer to the largest part of the information stored on a computer which can be searched together in the one search. So the CLIRS computer contains many different databases, not just one, because you cannot search all of the information on CLIRS at the same time.
The contents of databases may be as various as the information which may comprise them. However, it is useful to distinguish some major categories of information contained in databases:
(i) Conventional databases often require the information stored in them to be divided into separate fields, each of which may have a strict size limit (say 64 words), whereas free text systems can store data of variable and unlimited length;
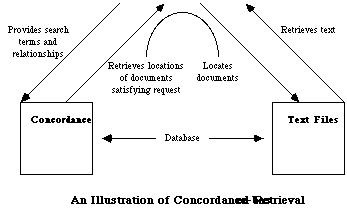
(ii) Conventional databases rely heavily on this strict field structure in order to retrieve information quickly, whereas free text systems use a special technique called a concordance, a word-occurrence index of the location of every word in the database. The concordance is explained in detail below.
In this Handbook, `retrieval system' is used synonymously with `free-text retrieval systems', unless stated otherwise. All of the types of information mentioned above are stored in free-text systems, although bibliographies and abstracts can be stored in conventional databases.
There are a number of different retrieval programs which may be used, most of which operate in a fashion similar to that which is outlined in the rest of this chapter. Bing's Handbook provides details of the main retrieval programs in use around the world. Other important retrieval programs from an Australasian point of view are STAIRS (used by AUSINET), BRS/SEARCH (used by KiwiNet) and the LEXIS retrieval program, discussed in Part C.

How do you instruct a computer to retrieve all such cases? Neither a computer nor a legal information retrieval system has any understanding of the legal system or legal concepts. Unless the retrieval system contained a list of all documents where these concepts were dealt with, it literally would not know where to look. Such a list would simply be a subject index of the database, and while that would no doubt be useful, it would bring with it many of the deficiencies of manual searching and would be a very minor advance.
Existing information retrieval systems commence from a completely different starting point. The basic assumption of most computerised retrieval systems is that the concepts we are searching for can be represented adequately by the words most commonly used to express those concepts . What an information retrieval system does is find all occurrences of specified words, or all occurrences of particular combinations of words, very fast. If a search request can be put in terms of words or combinations of words, the system can find all documents containing those words very quickly.
There are two methods by which most existing information retrieval systems retrieve documents containing words or combinations of words: concordance searching, and scanning. Understanding the difference between them is fundamental to understanding how information retrieval works.
While computers can make such comparisons very quickly, the types of computers used for information retrieval systems are generally not fast enough to carry out this type of sequential search over large databases. The most powerful computer in the world would have severe difficulties. It must be remembered that a database of caselaw may contain many thousands of cases, some of which will run for hundreds of pages of text. The computer may be able to carry out such a search in half an hour, which is, of course, very fast compared with how long it would take a person. However, such a `response time' - the time between when the user issues a command and when the computer provides a response - would be regarded by most users of information retrieval systems as unacceptably slow. No one is going to wait at a terminal for more than a minute or so without becoming impatient.
As a result, scanning is generally only used once a small number of potentially relevant documents have already been isolated. With a small number of documents, scanning commands may have a response time of seconds, or, at worst, a few minutes.

The location of an occurrence of a word in a database is recorded in the concordance as a set of numbers. For example, in such a system each database could be divided into numbered Chapters (eg a year of Law Reports), each Chapter into numbered Articles (eg one case), each Article into numbered and named Sections (specified parts of a document, such as the Title, the Headnote of a case, each Judgment, or the Longtitle of an Act), each Section into numbered Paragraphs, and each Paragraph into numbered Words. Therefore, each occurrence of each word in the database can be recorded as a unique five number set. The set (87, 23, 3, 15, 1) would mean the 1st Word of the 15th Paragraph of the 3rd Section of the 23rd Article in the 87th Chapter of a Database). The concordance can be thought of as an alphabetical list of words, with each word followed by as many of these four number sets as there are occurrences of that word in the database.
When a new document is added to a database, a retrieval program (STATUS, STAIRS, AIRS etc) is used by the system operator to `concord' the new document. In other words, all occurrences of words in the new document are added to the existing concordance.
An extract from the concordance of an AIRS database is included at the end of this chapter. It uses a 5 place concordance, as described above. The numbered Sections in the extract in the document are 1 - TITLE (the start of every article, although the word TITLE does not appear), 2 - SECT, 3 - NOTES, and 5 - LONGTITLE. In the example, you can see from the document that the word `animals' appears 5 times, and so there are 5 sets of 5 numbers listed under `animals' in the concordance. In Article 2 you will see that the expression `liability for damage' occurs. In the concordance this occurrence of `liability' is recorded as (2,2,5,1,5), `for' is (2,2,5,1,6) and `damage' is (2,2,5,1,7).
There are other ways of dividing up information which could be used to create a concordance. For example, paragraphs could be divided into numbered sentences, and the sentences then divided into words. However, each additional number in the concordance creates additional information which has to be stored in the computer. In most information retrieval systems, the concordance takes up at least as much storage space as the documents themselves, and additional levels in the concordance may make this ratio considerably worse than 1:1.
STATUS only uses a four level concordance, Section locations being recorded by the database creator allocating a maximum number of paragraphs for each Section. LEXIS and STAIRS do not record grammatical paragraph numbers. STAIRS records sentence numbers. These differences between retrieval systems need not concern you at this stage: the basic principles of the different systems are the same.
As an example, to find which documents satisfy the request Q trespass + children, the computer would first find in the concordance all locations of `trespass', and then compare this list with the list of locations for `children'. Since the request is for the words to appear in the same Article, this means that both the first and second numbers of the five number set must be the same for occurrences of each word.
As you might expect, there are even some special tricks by which the computer finds the correct entries in the concordance. It doesn't start at `aardvark' and proceed sequentially through the index until the desired words are found. Just as you have tabs in a dictionary indicating where the `T`s start and stop (ie where the`U's start), and you therefore go straight to the `T's to find `trespass', so there can be a similar `sparse index' to the concordance itself.
The search process using the concordance is illustrated in the diagram below.
In the STATUS search language, a plus sign (+) means AND, a comma (,) means OR and a minus (-) means NOT.
One way of thinking of these connectors is as relationships between sets of documents. For example, in the diagram below, A could represent the set of documents in a database containing the word `trespass', and B the set of documents containing the word `children'. The relationships between the sets of documents, and how they are expressed in the STATUS search language, then follow.

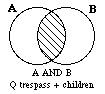
Q trespass // children is the instruction given to retrieve all documents where `trespass' and `children' occur in the same paragraph of the same article, and
Q trespass /3/ children means that the two words must occur not only in the same paragraph, but that `children' must follow three words after `trespass'.
In the example following, a search for
Q liability /2/ damage
would find the phrase `liability for damage', because this occurrence of `liability' is recorded as (2,2,5,1,5) and `damage' is (2,2,5,1,7), and so the distance between the words is 2 words as specified.
| `and' | + | chapter | article | |||
| `or' | , | chapter | article | |||
| `not' | - | chapter | article | |||
| `within a Section' | @ | section | ||||
| `same paragraph' | // | chapter | article | section | paragraph | |
| `n words after' | /n/ | chapter | article | section | paragraph | word |
When the retrieval program is carrying out a search which uses one of the logical connectors (+ , - ) it need only compare the concordance numbers for the connected words at the first two levels of the concordance, Chapter and Article. When the @ connector is used, the numbers at the third level, section, must also be compared. When the // connector is used, the numbers at the fourth level, Paragraph, must also be compared. When the /n/ connector is used, the numbers at the fifth level, Word, must also be compared.
The use of these logical and positional connectors in STATUS is explained fully in Chapters 10 and 11. As mentioned earlier, the way in which STATUS implements Sections is different from the explanation given above for AIRS.
(i) The databases (information), consisting of two parts:
(a) the documents, or text files; and
(b) the concordance, or word occurrence index.
(ii) The retrieval program (software) performing two main functions:
(a) to allow the system operator to build the concordance from the documents; and
(b) to provide a search language used by the users of the system to retrieve documents, based on logical (Boolean) and proximity connectors.
In the next chapter, some deficiencies of existing retrieval techniques, and suggested improvements, are discussed.
The second extract is the Concordance file for a concordance of those 3 articles alone. In the real concordance for the whole Act, references to all the other sections of the Act would appear, and some words might have hundreds of entries.
1 How many concordance entries are there for the word `1977'? What is the first one? Is is correct?
2 What is the concordance entry for the occurrence of `animals' where it occurs in the phrase `caused by animals'?
3 The concordance entries for the words `New South Wales' in the last
paragraph have been omitted. What should they be?
Document
CHAPTER 2
ARTICLE 1
ANIMALS ACT, 1977, No. 25
#DATE 23:05:1979
Reprinted as at 23rd May, 1979
Current as at 31:12:1985 CLIRS
NOTES
(1) Animals Act, 1977, No. 25. Assented to, 13th April, 1977.
Note.--This Act is reprinted with the omission of all amending provisions
authorised to be omitted under s.6 of the Acts Reprinting Act,
1972.
ARTICLE 2
ANIMALS ACT, 1977 - LONG TITLE
LONGTITLE
An Act relating to liability for damage caused by animals.
ARTICLE 3
ANIMALS ACT, 1977 - PREAMBLE
SECT
BE it enacted by the Queen's Most Excellent Majesty, by and with
the advice and
consent of the Legislative Council and Legislative Assembly of
New South Wales
in Parliament assembled, and by the authority of the same, as follows:--
Concordance
Chapter Article Section Para Word
05 2 1 1 1 8
1 2 1 3 1 1
12 2 1 1 1 20
13TH 2 1 3 1 9
1972 2 1 3 2 25
1977 2 1 1 1 3
2 1 3 1 4
2 1 3 1 11
2 2 1 1 3
2 3 1 1 3
1979 2 1 1 1 9
2 1 1 1 15
1985 2 1 1 1 21
23 2 1 1 1 7
23RD 2 1 1 1 13
25 2 1 1 1 5
2 1 3 1 6
31 2 1 1 1 19
6 2 1 3 2 19
ACTS 2 1 3 2 22
ADVICE 2 3 2 1 15
ALL 2 1 3 2 10
AMENDING 2 1 3 2 11
ANIMALS 2 1 1 1 1
2 1 3 1 2
2 2 1 1 1
2 2 5 1 10
2 3 1 1 1
APRIL 2 1 3 1 10
ASSEMBLED 2 3 2 1 31
ASSEMBLY 2 3 2 1 24
ASSENTED 2 1 3 1 7
AUTHORISED 2 1 3 2 13
AUTHORITY 2 3 2 1 35
CAUSED 2 2 5 1 8
CLIRS 2 1 1 1 22
CONSENT 2 3 2 1 17
COUNCIL 2 3 2 1 21
CURRENT 2 1 1 1 16
DAMAGE 2 2 5 1 7
ENACTED 2 3 2 1 3
EXCELLENT 2 3 2 1 9
FOLLOWS 2 3 2 1 40
FOR 2 2 5 1 6
IT 2 3 2 1 2
LEGISLATIVE 2 3 2 1 20
LIABILITY 2 2 5 1 5
LONG 2 2 1 1 4
MAJESTY 2 3 2 1 10
MAY 2 1 1 1 14
MOST 2 3 2 1 8
NEW ******** OMITTED *********
NO 2 1 1 1 4
2 1 3 1 5
NOTE 2 1 3 2 1
OMISSION 2 1 3 2 8
OMITTED 2 1 3 2 16
PARLIAMENT 2 3 2 1 30
PREAMBLE 2 3 1 1 4
PROVISIONS 2 1 3 2 12
QUEEN 2 3 2 1 6
RELATING 2 2 5 1 3
REPRINTED 2 1 1 1 10
2 1 3 2 5
REPRINTING 2 1 3 2 23
S 2 1 3 2 18
2 3 2 1 7
SAME 2 3 2 1 38
SOUTH ******* OMITTED *********
TITLE 2 2 1 1 5
UNDER 2 1 3 2 17
WALES 2 3 2 1 28
WITH 2 1 3 2 6
2 3 2 1 13
Note that the words a, act, and, as, be, by, is, of, the, to are not concorded - they are common words.
2 animals 2 2 5 1 10
3 New 2 3 2 1 26
South 2 3 2 1 27
Wales 2 3 2 1 28
