|
|
|
Reading Guide:
Hypertext and Retrieval
5. Global legal research on the Internet
|
|
|
[Previous]
[Next] [Title]
[This Part is not yet complete for 2000 - it will be revised and expanded considerably.]
Some of the factors that make legal research on the internet different from legal
research using a CD-ROM, a single dial-up system (eg Lexis), or a litigation support
system are:
- That research may be across multiple sites on the web (often world-wide).
- Wide use of relevance ranking systems (see earlier).
- The role of web spiders or robots to build searchable collections of remote
documents.
- The increasingly complex relationship between directories (hypertext-based
structured sets of links) and search engines.
- The (potential) role of meta-tags to provide some control over search engine
behaviour to the developers of web pages.
This Part first discusses internet-wide search and indexing tools, and then moves
to a discussion of specialist tools dealing with legal information.
Two general resources referred to often in this Part are:
Internet-wide search engines are based on the interaction of at least three programs:
a web spider (also known as web robot or web crawler), a program that creates
a concordance (index) for searching, and a search engine. Here are some explanations
of how they interact, as background to later more detailed discussion of search
engines:
There is relatively little research as yet about the difficulties of legal
research on the internet, as distinct from internet research generally (see below),
on which much has been written.
See  2. The Problem
- Internet Legal Research is Difficult (in Greenleaf et al 1999) for a 1999
discussion of the difficulties of using internet-wide indexes and search engines
and indexes for legal research.
2. The Problem
- Internet Legal Research is Difficult (in Greenleaf et al 1999) for a 1999
discussion of the difficulties of using internet-wide indexes and search engines
and indexes for legal research.
For an older (1998) but in some respects more detailed discussion, see
Chapter 2.- Legal research via the Internet - Potential and problems' (Greenleaf
1998). The parts of this Chapter that are most useful here are:
In Greenleaf et al 1999, these problems of general search engines for legal research
were summed up as:
- They are not comprehensive - see Lawrence and Giles 1999, discussed below
- expansion to 800M web pages is core problem
- best coverage is 16% (Northern Light)
- coverage declined from 33% in 1997 to 16% in 1999
- Even meta-search engines could give 42% at best
- Many other reasons why they are not comprehensive
- Diminishing economic returns in increasing coverage?
- General search engines are often out of date
- General search engines contain too much `noise'
- General search engines are biased in favour of 'popular' pages
- General search engines do not provide unbiased world-wide coverage
- Some are selling priority places in their relevance ranking
Are these reasons still correct, even just a year later?
There is a great deal of published research on the effectiveness of various internet-wide
research tools (ie those which are not restricted to legal information).
Some of the more useful sources are discussed below, with the most recent
information first::
Greg Notess Search Engine Showdown
site appears to do attempt an independent evaluation of the claims of coverage
of search engines, as seen from the following pages (as at 7 July 2000):
- Database
Total Size Estimates, which shows that the best performing search engines
on his tests seemed to cover 300-350M pages (compared with their own claims
of 500-560 M).
- 'Relative
Size Showdown' - This test of total hits from 33 searches places iWon
and Google as the two search engines providing the largest numbers of hits
in a comparison of searches. [However, we should question whether that is
a particularly meaningful statistic - read the report.]
- The percentage of http://www.searchengineshowdown.com/stats/dead.shtml
dead links in search resultsis as high as 13.7% (Alta Vista), but only 2.3%
for Fast.
A commonly quoted estimate of the total number of web pages as at mid-2000 is
1 billion web pages, which if correct would means that the best search engines
are now covering about 30-35% of the total web. In Lawrence and Giles 1999 study
(below), the estimate was that the best search engine then covered 15% of a total
800M web pages.
One of the most extensive general resources is Search
Engine Watch edited by Danny Sullivan. It's a huge site and easy to get lost,
so you might like to start with the
guide to first-time visitors. It is updated constantly, and has a very informative
monthly newsletter
to which anyone who is seriously interested in search engines is likely to
subscribe.
Aspects of the site that you might wish to look at include:
- Search Engine
Status Reports - an extraordinary array of comparisons of the different
search engines.
- The
report on Search
Engine Sizes As at its 7 July 2000 report, Search Engine Watch accepts
an estimate of 1 billion web pages at at February 2000 (up from 8000 million
estimated by Lawrence and Giles in early 1999). It states that Google
now has the broadest coverage, with 56% claimed coverage (560M
web pages), with WebTop and Inktomi second with 500M pages each, and AltaVista
fourth with 350M (35% coverage). ( In mid-1999 his report indicated that Alta
Vista was clearly the search engine with the broadest coverage, followed by
Inktomi (Hot Bot) and Northern Light, and with the others well behind. See,
in contrast, Lawrence and Giles below).
- His graphs also show the vastly increased claims of coverage by
all of the major search engines over the past 12 months, with all admitting
coverage no greater than 150M pages in June 1999 (consistent with Lawrence
and Giles claim of no more than 15% coverage), but with claims in June 2000
of over 350Mpages, and claims by Google and Inktomi in July 2000 of even more
rapid (almost instant) escalation to over 500M pages, these claims must be
treated with some scepticism.
- The Search
Engine Size Test is also interesting, but depends for its methodology
on accepting the claimed coverage of one search engine, and then measuring
the expected performance of other search engines (based on their claims) against
that. This is an odd approach, which seems to assume that 'they can't all
be lying'.
-
The Major Search Engines - a valuable comparison and explanation of the
major internet-wide search engines.
A study by Lawrence and Giles (Lawrence S and Giles C L (1999) 'Accessibility
of information on the Web' Nature, Vol 400, 8 July 1999, pgs107-9 (Macmillan,
UK)), argued that the best search engines (in early 1999) only covered 15% of
the estimated 800M web pages, after adjustment for bad links. Northern Light,
Snap and AltaVista were roughly equal. It is important that this research was
based on the author's independent assessments of what percentage of web pages
each search engine covered, not the search engines' self-reporting assessments
of what they cover.
The article is not available in full for free on the web, but see some of the
following:
Susan Feldman
Web search services
in 1998: Trends and challenges (1998) Searcher Vol 6 No 6 - A superb survey
which includes criteria for evaluation of search engines, trends, and a comparative
table of major search engines.
Some items to note from Feldman's paper.:
- No single search engine goes close to making the whole world-wide-web searchable:
'Results show little overlap between search engines, so use more than one.'
She cites evidence that 'the overlap is at best about 34 percent.'.
- 'Most sites recognize that a combination of browsing categorized pages
and direct query serves users best.'. So it seems some combination of intellectual
indexing and free-text searching is being accepted as providing the best results.
- ' Most of the search companies have developed a precise search feature
which allows Boolean searching, in addition to their standard statistical
interface for the broad query.' (A 'statistical interface' refers to pure
relevance ranking without boolean operators, whereas the reference to 'Boolean
searching' is to boolean searching where the results are then ranked for relevance.)
- Development of multi-language search capacities and various forms of on-line
translation capacities is an active field of research at present.
- 'Metatags' - 'descriptors' or subject headings or indexing terms which
are not visible to the user of a page but can be read by search engines -
are not utilised by search engines as much as we might expect. One reason
given is that although about 30% of web pages have metatags, 90% of those
are 'spam' (also called 'metatag stuffing'), 'misleading terms or repeated
terms to make their site come up in the top 10 listed, or in completely irrelevant
search results'. Many search engines therefore simply ignore metatags.
- Among the various means of funding the operation of search engines, 'Charges
for preferential listings' is listed as an increasingly popular option. This
means that some search engine companies sell the highest ranking positions
in their (so-called) relevance ranked lists of search results (ie the rest
of the results might genuinely be ranked in order, but the top-ranking spots
are simply sold). Amazon.com has been subjected to heavy criticism for a similar
practice. The ethics/transparency of relevance ranking.
- How does Feldman's 'wish list' compare with yours?
These conclusions seem generally consistent with what is argued in the Project
DIAL Report.
Feldman's Search Engine Feature
Chart (at the end of the article) compares the features of eight
search engines (and associated directories).
Other valuable articles by Susan Feldman:
- The Answer
Machine Searcher, Volume 8, Number 1
* January 2000 - Some of the futures of information retrieval.
- Where do we put the web search engines? (Searcher, November 1998)
is also an excellent account of web search strategies, providing tips on how
to use many of these search engines.
- Searcher magazine - Monthly
journal for information professionals which puts the full text of many of
its articles online. First class resource.
The problems of internet-wise research tools have led to a search for discipline-specific
approaches to finding internet-wide information. One solution has been to combine
an internet index for a discipline such as law with a web spider that only goes
to sites listted in that index and does not 'wander off' to other sites. This
is variously called a 'limited area search engine' (LASE) or a 'targeted web spider'
3.5 Other
Limited Area Search Engines (Greenleaf et al 1999) discusses a number of
such LASEs.
<IMG ALIGN=MIDDLE SRC="http://www2.austlii.edu.au/itlaw/required.gif">
3.1 A New Technical
Solution - A Limited Area Search Engine for Law (Greenleaf et al 1999) explains
the approach taken in AustLII's World Law since 1997.
Danny Sullivan
Getting off the beaten track: Specialized web search engines (Searcher October
1998) reviews various types of specialised search engines.
The Institute of Advanced Legal Studies in London and the University of Bristol
Law Library have since late 1999 started the
SOSIG Law Gateway as part of the UK' s Social Science Information Gateway
(SOSIG) project:
The SOSIG Law Gateway provides guidance and access to global legal
information resources on the Internet.The service aims to identify and evaluate
legal resource sites offering primary and secondary materials and other items
of legal interest.'
The most detailed description of the Law Gateway is Steven Whittle
A National Law Gateway : developing SOSIG for the UK Legal Community, Commentary
2000 (2) The Journal of Information, Law and Technology (JILT).

Law Gateway home page - <http://www.sosig.ac.uk/law/>
Some noteable aspects of the Law Gateway:
- It aims to evaluate, not just to identify and link.
- It aims for global
coverage;
- Its email notification service ('current awareness service').
- Its indexing standards.
Whittle's article states that:
A Social Science Search Engine is also provided - this is a limited
area search engine drawn from a supplementary database of over 50,000 links
gathered by a web robot which visits each of the quality websites featured in
the Catalogue (including all the Law section sites) and follows any links it
finds for those pages and automatically indexes the content.
It seems that the way this works is that, if a search using the search engine
on each page of the Law Gateway fails to find a record in the catalog, only then
does the system offer another search over the full text of law (and other) sites
to which the web robot has been sent. For example, try a search for 'domain names',
and it gets no results by searching the catalog, but finds four items from the
full text search.
World/
World Law is the global index and search facility on AustLII. h Project
DIAL s a part of World Law (the Asian Development Bank funds the legislation
and Asian emphasis, and training in some Asian countries) but there is no signigicant
technical difference between World Law and DIAL.
Graham
Greenleaf et al
Solving the Problems of Finding Law on the Web: World Law and DIAL', 2000
(1) The Journal of Information, Law and Technology (JILT) gives the most
detailed recent (1999) account of World Law.

There is a User Guide
or a Quick
Guide which helps explain how it works.

The main features of World Law that are worth noting are:
- Global coverage
- but for some countries this is mainly through an embedded search.
- Each site added to the index is usually catalogued under multiple nodes:
by country; by source or type of document; and by a subject index. This gives
considerable flexibility in how the data may be accessed, and in the search
combinations that are possible.
- Searches from any point in World Law return two sets of results: (i) all
web pages where the search terms are found, by a full text search of all sites
to which the web spider has been sent; and (ii) all directories in the index
(catalog) where the search terms are found. So, both the catalog are searchable,
and the full text of sites to which the web spider is sent.
- The scope of a full text search of the web spider materials is limited
by where you search from (the context). - limited
scope searches.
- A 'Search
this site' facility allows the full text of individual web sites to be
searched.
- The index also contains stored searches - see
6. Storing Searches to Create a Self-Maintaining Index
- There are an increasing number of outside contributors to maintainig the
index - see
3.3 International Indexing Partnerships - A Necessary Element (in Greenleaf
1999)
The Open Directory Project (ODP) explains
in <IMG ALIGN=MIDDLE SRC="http://www2.austlii.edu.au/itlaw/required.gif">
About the Open Directory Project that
its goal is 'to produce the most comprehensivedirectory of the web, by relying
on a vast army of volunteer editors' because 'As the web grows, automated search
engines and directories with small editorial staffs will be unable to cope with
the volume of sites. '
Features of the ODP are:
- Everyone is invited to become editors:
Like any community, you get what you give. The Open Directory
provides the opportunity for everyone to contribute. Signing up is easy: choose
a topic you know something about and join. Editing categories is a snap. We
have a comprehensive set of tools for adding, deleting, and updating links in
seconds. For just a few minutes of your time you can help make the Web a better
place, and be recognized as an expert on your chosen topic.
- The resulting data is available for anyone else to re-use in other projects,
in whole or part. See the Free use
license for the Open Directory data
- ODP does not have its own search engine, but ODP data is being used with
other commercial search engines, including Netscape, Lycos, HotBot, and others
- See
Sites using Open Directory data.
The <IMG ALIGN=MIDDLE SRC="http://www2.austlii.edu.au/itlaw/required.gif">
Law subdirectories of ODP have over
11,000 entries (as at August 2000). The best way to gain an appreciation of whether
ODP is likely to be effective to produce an effective legal research tool is to
look at a selection of ODP entries and gain an idea of the range and quality of
its coverage. Is it genuinely international? What do most of the 11,000 entries
concern?

For further information, see:
The US Library of Congress'
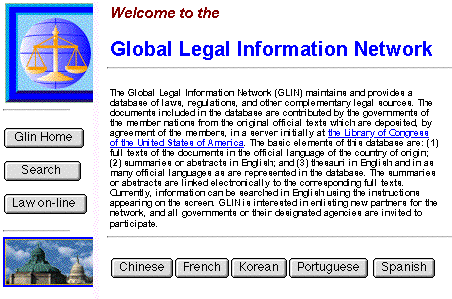
GLIN (Global Legal Information Network) is not a limited area search engine,
but is the most ambitious centralised collection of laws yet undertaken other
than the commercial LEXIS system. Its home page explains its purpose:
The Global Legal Information Network (GLIN) provides a database
of national laws from contributing countries around the world accessed from
a World Wide Web server of the U.S. Library of Congress. The database consists
of searchable legal abstracts in English and some full texts of laws in the
language of the contributing country. It provides information on national legislation
from more than 35 countries, with other countries being added on a continuing
basis.
See
2.7.1. Global Legal Information Network (GLIN) (Greenleaf 1998) for a summary
of GLIN (as at 1998).
[This part is not finished for 2000 - more to come]
[Previous] [Next]
[Title]